

Par Amir BENYEKKOU – Ingénieur Systèmes, Virtual Infrastructure chez Squad
Ce second article traite des problématiques relatives à un environnement VMware vSphere où la sur-allocation de ressources peut entraîner des baisses de performances des charges de travail virtualisées. Seul le troubleshooting relatif aux hyperviseurs ESXi sera abordé. Les problématiques de performances liées à la configuration des fonctionnalités cluster et HA VMware vSphere ne seront pas abordées ici.
Pour chaque composant CPU, Mémoire, Réseau, Stockage il existe des compteurs spécifiques à monitorer pouvant révéler le manque d’optimisation de l’infrastructure virtualisée. Ces compteurs peuvent être monitorés par le client graphique incorporé à la console web pour une approche de gestion de la capacité ou bien en ligne de commande pour une approche orientée troubleshooting.
Pour obtenir les meilleures performances d’un environnement, il faut suivre deux pratiques :
- Comprendre les besoins des applications et les caractéristiques des charges de travail
- Optimiser la configuration des VMs pour offrir le meilleur environnement aux charges de travail.
Schéma de Troubleshooting
Le schéma suivant représente le processus basique de troubleshooting d’un hôte ESXi. La liste à vérifier couvre la plupart des problèmes de performances sur un ESXi :
- Problèmes directs : problèmes qui ont un effet direct et qui doivent être corrigés.
- Problèmes courants : conditions qui ont un effet direct sur les performances la plupart du temps
- Problèmes possibles : conditions pouvant être des indicateurs mais peuvent aussi refléter des conditions normales de fonctionnement.
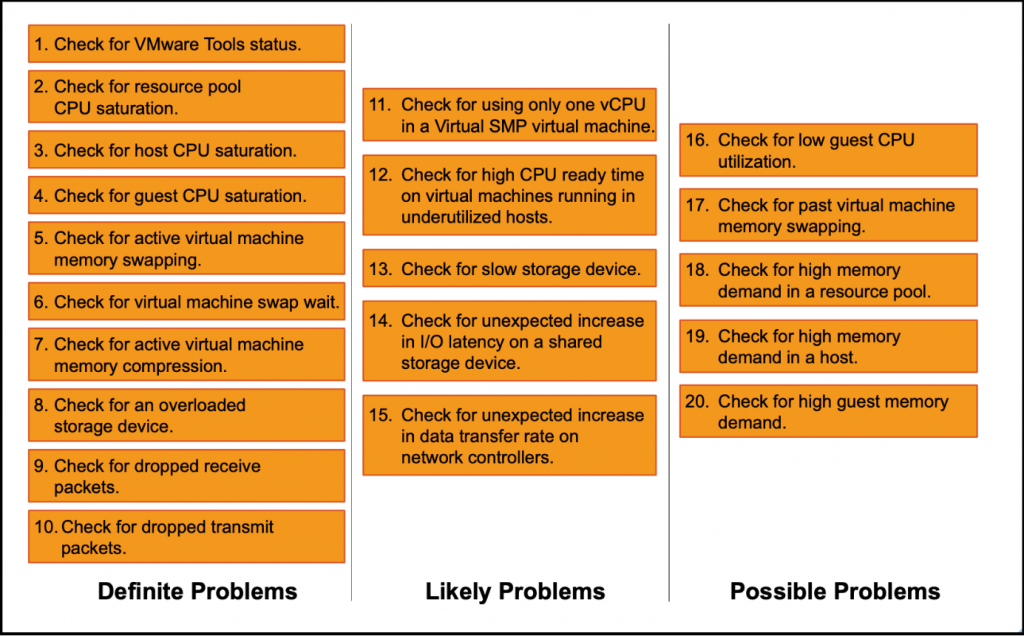
L’ensemble de ces problèmes peuvent être identifiés à l’aide du client de monitoring VMware vSphere ou bien avec l’utilitaire esxtop en ligne de commande sur le vCenter ou les hôtes ESXi.
Troubleshooting des performances Réseau
L’outil esxtop ainsi que d’autres outils permettent de visualiser l’état du réseau à un instant donné aussi bien sur les vSwitch de l’hôte ESXi que sur les cartes réseaux virtuelles des machines virtuelles.

Les indicateurs à afficher peuvent être paramétrables. Les deux indicateurs les plus significatifs sont les paquets ignorés en émission/réception (%DRPTX & %DRPRX)
Si le taux de paquets ignoré en réception est > 0 :
- La cause peut être une utilisation CPU intensive au sein de la VM et il faut dans ce cas soit augmenter les ressources CPU délivrées à la VM ou améliorer l’efficacité d’utilisation des ressources CPU par la VM
- Ou une configuration incorrecte des pilotes réseau de la VM et il faut améliorer la prise en charge de la pile réseau ou répartir la charge réseau
Si le taux de paquets ignoré en émission est > 0 :
- Le trafic des machines virtuelles rattachées au même vSwitch dépasse la capacité physique des cartes Uplinks ou de l’infrastructure réseau physique sous-jacente. Dans ce cas il faut rajouter des uplinks sur le vSwitch, équilibrer la charge réseau des machines virtuelles en les déplaçant sur d’autres vSwitchs, améliorer la capacité du réseau physique ou bien diminuer le trafic réseau.
Il conviendra également de vérifier les informations collectées avec celles du réseau physique sous-jacent.
Si le taux de transfert de données s’accroît très rapidement (MBTX/s ou MBRX/s) :
Les ressources réseaux sont en contention du fait que plusieurs fonctionnalités se partagent un même lien physique (vMotion ou Fault Tolerance par example). Dans ce cas mettre en place des partages, réservations et limites avec Network IO Control pour distribuer le trafic parmi les différents types de flux réseaux.
Troubleshooting des Performances du Stockage
Plusieurs indicateurs seront à prendre en considération avec esxtop et il faudra comparer ces indicateurs sur 3 niveaux : adaptateur de stockage physique (carte HBA), périphérique de stockage physique (LUN), disque virtuel de machine virtuelle.
Les indicateurs clés à analyser seront :
- Le débit des disques
- La latence noyau et périphérique
- Nombre de commandes disques en échecs, actives et en file d’attente.


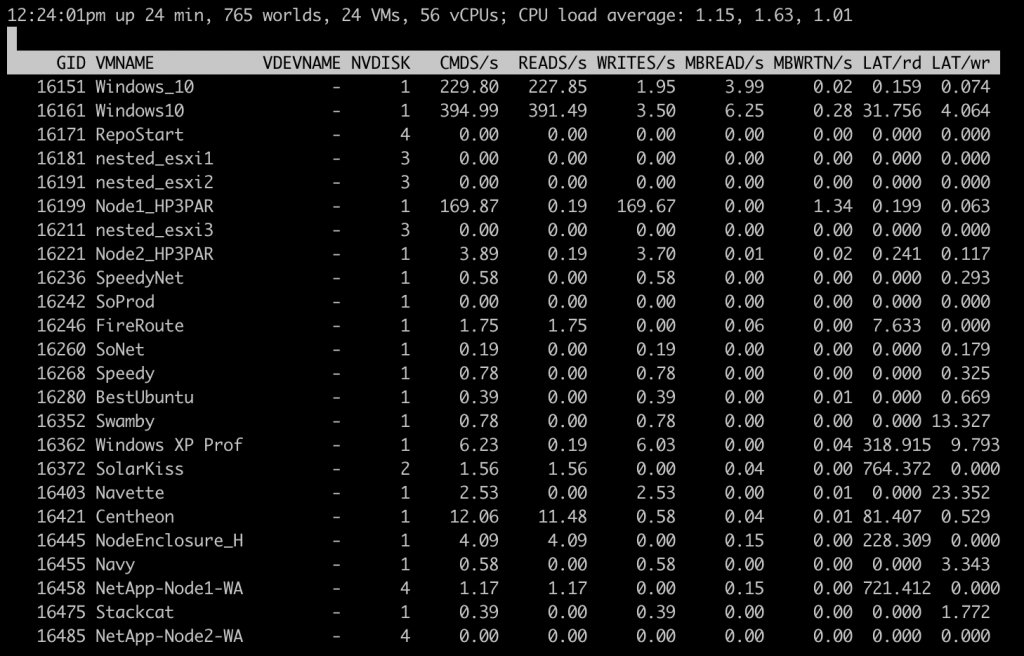
La sommes des Reads/s et Writes/s est égale aux IOPS et permet de vérifier si les IOPS ne sont pas à la limite du stockage sous-jacent.
Sur la vue des cartes HBA :
Les indicateurs DAVG/cmd et KAVG/cmd représentent respectivement la latence moyenne en milliseconde du périphérique et du VMKernel.
Le premier indicateur correspond au temps moyen mis par un périphérique physique pour compléter une commande SCSI, cette métrique définit le temps pris par le périphérique physique en partant de la carte HBA jusqu’au système de stockage sous-jacent.
Le second correspond au temps moyen passé par le VMKernel pour traiter une commande SCSI, cette métrique mesure le temps entre l’OS de la VM et son périphérique virtuel.
Si le premier indicateur est > 20 alors le LUN est lent ou surchargé ; s’il est compris entre 10 et 20 cela peut représenter un potentiel problème de performance
Si le second indicateur est > 2 ms alors les VMs essayent d’envoyer plus de débit que le stockage sous-jacent peut supporter
La latence totale d’une VM est la somme de la latence de périphérique (DAVG) et VMkernel (KAVG). Si l’indicateur est > 10 un problème peut exister et s’il est > 20 un problème de performance est présent.
Sur la vue des LUN :
Le nombre de commandes actives et en file d’attente (ACTV & QUED) sur les LUN permet de mettre en évidence une éventuelle contention des LUN. Si le nombre de commandes actives atteint la profondeur maximale de la file d’attente (DQLEN) alors les commandes seront placées en file d’attente avec pour conséquence une augmentation de la latence.
Le nombre de commandes en échecs (ABRT/s) sur les LUN permettent de voir si l’un d’eux est surchargé. Dans ce cas il faudra regarder sur la configuration du niveau de RAID, du cache ou du nombre de disques par LUN est en adéquation avec les exigences des charges de travail.
Vsphere Storage IO Control permet de contrôler plus finement les allocations par VM afin de réduire les contentions sur les ressources de stockage.
Enfin la vue VM permet d’avoir une vision plus fine sur les VMs et de pouvoir tracer un problème de performance de bout en bout.
Troubleshooting des Performances du processeur
Les indicateurs liés aux performances du processeur sont semblables à ceux que l’on peut trouver sur des systèmes Linux traditionnelles avec quelques spécificités liés à la virtualisation et aux machines virtuelles
Les indicateurs clés sont :
- CPU utilisé sur l’hôte ESXi
- CPU utilisé par VM
- CPU Ready par VM
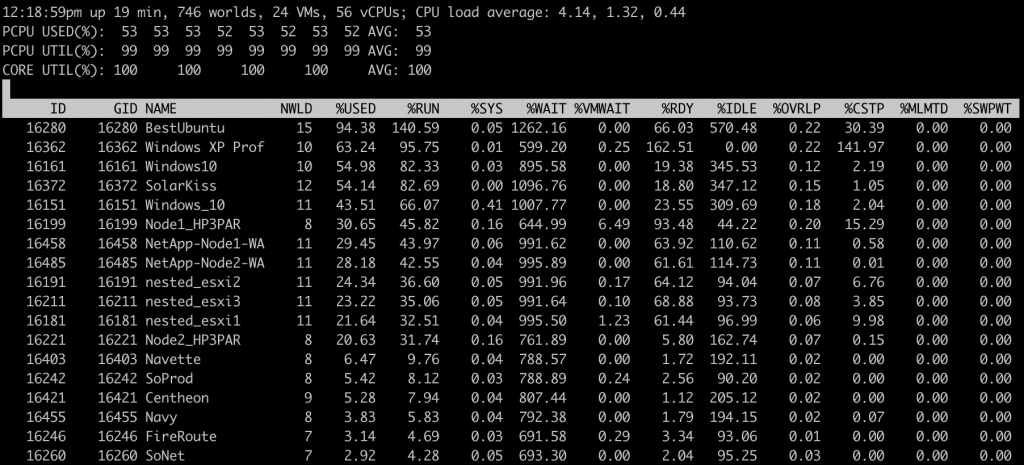
Les indicateurs d’esxtop les plus importants sont :
- %PCPU Used = Pourcentage d’utilisation par CPU physique
- %USED : Pourcentage d’utilisation CPU par VM
- %SYS : Pourcentage du temps passé par le VMKernel pour la gestion des interruptions
- %RDY : Pourcentage de temps ou une VM était prête à exécuter des instructions mais aucune ressource CPU physique n’a été attribué
- %WAIT : Pourcentage de temps passé à l’état occupé ou bloqué par une VM
Des valeurs hautes d’utilisation CPU n’indiquent pas forcément un problème de performance puisque c’est l’un des buts des environnements virtualisés. En corrélation avec de hautes valeur de file d’attente côté Réseau cela peut indiquer un potentiel problème.
L’indicateur « ReadyTime » indique s’il y a plus de ressources CPU demandant à être planifiés sur les CPU physiques de l’hôte. Ces requêtes sont mises en attente par le CPU scheduler de l’hôte car les CPU physiques sont déjà surchargés.
Si cet indicateur est > 10%, il convient d’analyser la charge de travail de la VM :
- Suivre les bonnes pratiques de configuration applicative sur la VM
- Choisir le bon nombre de CPU pour la VM
- Utiliser des larges pages mémoires
- Ajuster les limites, réservations et mémoire de la VM
- Augmenter l’allocation de CPU sur la VM si l’OS invité et ses applications consomment toutes les ressources CPU.
Mais également de regarder s’il n’y a pas surallocation de vCPUs par rapport aux CPU physiques sur l’hôte.
Troubleshooting des performances Mémoire
Les techniques énoncées lors du premier article peuvent être mise en évidence par les différents indicateurs d’esxtop.
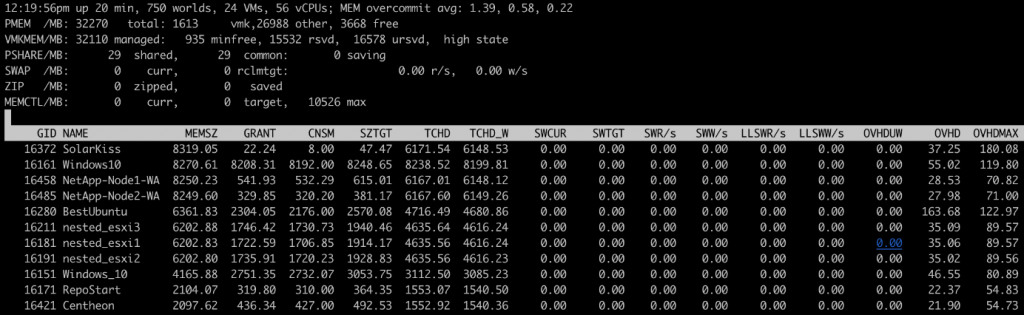
Plusieurs indicateurs clés sont à observer :
- PMEM : Mémoire physique ESXi, la somme de vmk, other et free donne la mémoire physique totale
- VMKMEM : Mémoire totale gérée par le VMKernel, la somme de la mémoire réservée, non réservée et du vmkernel sur la ligne PMEM. Ainsi que l’état (ici high state). Plus l’état est bas plus les différentes techniques d’optimisation mémoire ont été exécutés.
- PSHARE : Les statistiques de mémoire après le passage du Transparent Sharing
- SWAP : La mémoire total paginée par les machines virtuelles avec le SWR/s et SWW/s (Débit en Mo de Lecture/écriture pour chaque VM)
- ZIP : Taille mémoire compressée par l’hôte ESXi
- SWCUR : Le montant de l’espace swap utilisé par la VM.
- SWTGT : Le montant de l’espace swap que l’hôte ESX s’attend à être utilisé par la VM.
- MEMCTL : Les statistiques de Ballooning (réclamation mémoire aux autres VMS en cas de contention
- MEMCTL ? : Indique si les vmtools sont installés sur chaque VM ou pas afin de pouvoir faire du ballooning
- MCTLSZ : Mémoire réclamée par le ballooning sur chaque VM
Les états affichés sur la console (high state, clear, soft, hard, low) permettront d’aiguiller le diagnostic et de comprendre qu’à chaque dégradation de l’état général, les techniques pour économiser de la mémoire seront utilisées l’une après l’autre. Ces états sont atteints soit par une surallocation mémoire ou bien par un trop grand nombre de VM sur l’hôte.
Dans ce cas on peut migrer les VMs et pour avoir une solution pérenne effectuer la métrologie de consommation mémoire de chaque VM afin de redéfinir l’allocation ou encore les limites/réservations sur les VMs.
Article à relire :
VMWare Vsphere : Optimisation des performances

